Flip Flop ေတြမွာ Counter အလုပ္လုပ္တာကို ျမင္ဖူးပါလိမ့္မယ္ ဒီေတာ့ အလုပ္ျမန္ျမန္လုပ္ေစခ်င္ရင္ Clock ကိုျမန္ျမန္ေပးရမွာေပါ့။ Processor ကိုလည္း အဲဒီလိုပဲယူဆလိုက္ပါ သူလည္းအတူတူပါပဲ Clock Trigger ျဖစ္မွပဲသူလည္း အလုပ္တစ္ခါ လုပ္ပါတယ္။ Processor ရဲ႕အလုပ္ကေတာ့ တစ္ျခား Device ေတြလိုမဟုတ္ပဲ အလုပ္ေတြက ဝင္လာတဲ့ Instruction အေပၚမတည္ၿပီးေတာ့ အလုပ္ကလုပ္ေပးရတာပါ။ Instruction မွာက အလြယ္ေျပာမယ္ဆိုရင္ အလုပ္ကတစ္ခုတည္း မဟုတ္ပါဘူး တစ္ခုထက္ပိုပါတယ္ အဲဒါေၾကာင့္ Clock တစ္ခုမွာ အလုပ္ကတစ္ခုပဲ လုပ္ႏိုင္တဲ့အတြက္ Single Instruction မွာဆိုရင္ Multiple Clock လိုအပ္တာပါ။
ေယဘုယ်အားျဖင့္ RISC Processor ေတြမွာ Instruction တစ္ခုအတြက္ လုပ္ရမယ့္အလုပ္ေတြကို ေအာက္မွာျပထားသလို အဆင့္နဲ႔ခြဲထားပါတယ္။
- Instruction Fetch (IF)
- Instruction Decode (ID)
- Execute (EX)
- Memory Access (MA)
- Write Back (WB)
အလုပ္တစ္ခုဟာ Clock တစ္ခုလုိအပ္တဲ့အတြက္ Instruction တစ္ခုအတြက္ အဆင့္ငါးဆင့္ လုပ္ရမွာျဖစ္လို႔ ပံုမွန္အားျဖင့္ Clock ငါးခုလိုအပ္ပါတယ္။ နမူနာအျဖစ္ အလုပ္လုပ္ပံုကို ေျပာရမယ္ဆိုရင္ 680x0 Instruction နမူနာတစ္ခုအျဖစ္ move.l (a1), d1 ဆိုတာ Memory တစ္ေနရာမွာ ရွိတယ္ဆိုၾကပါစို႔ အဲဒါဆိုရင္ ပထမအဆင့္ IF အေနနဲ႔ အဲဒီ့ Instruction ကို သက္ဆိုင္ရာေနရာကေန ဖတ္ပါတယ္ ဒုတိယအဆင့္ ID အေနနဲ႔ Instruction ကိုဘာလုပ္ခိုင္းသလဲ ခြဲျခားရပါတယ္ ခြဲျခားလိုက္မယ္ဆိုရင္ move လုပ္ရမယ္ လုပ္ရမယ့္ Size က Long ျဖစ္တယ္ a1 ထဲမွာရွိတဲ့ Address မွာသိမ္းထားတဲ့ data ကို d1 ဆိုတဲ့ Register ထဲကိုကူးထည့္ရမယ္လို႔ ခြဲျခားႏိုင္ပါတယ္။ တတိယအဆင့္ EX အေနနဲ႔ သူေျပာထားတဲ့အလုပ္ကို ALU အေနနဲ႔လုပ္ဖုိ႔လိုအပ္ပါတယ္ Execute လုပ္ဖို႔အတြက္ ဒီအတိုင္းလုပ္လို႔မရပါဘူး a1 ထဲမွာရွိတဲ့ Address မွာသိမ္းထားတဲ့ data ကိုဖတ္ဖို႔လိုတဲ့အတြက္ Processor ထဲက Data နဲ႔မလံုေလာက္လို႔ Memory ကို Access လုပ္ဖို႔လိုပါတယ္ အဲဒီ့လိုလုပ္တဲ့အလုပ္ကို စတုတၳအဆင့္အေနနဲ႔ MA လို႔ေျပာလို႔ရမွာျဖစ္ပါတယ္ ေနာက္ဆံုးအဆင့္အေနနဲ႔ ထြက္လာတဲ့အေျဖကို သက္ဆိုင္ရာ ေနရာမွာသြားေရးရပါတယ္ ဒီ Instruction မွာေတာ့ ဖတ္လို႔ရတဲ့ Data ကို d1 ထဲကိုသြားေရးပါတယ္ ဒါဆိုရင္ ပဥၥမအဆင့္ျဖစ္တဲ့ WB ၿပီးဆံုးပါလိမ့္မယ္။ အဲဒါဆိုရင္ေနာက္ထပ္ Instruction တစ္ခုကိုထပ္ဖတ္တဲ့ IF ကေန WB အထိဆက္လုပ္ရင္ Processor ကိုမပိတ္မခ်င္း ဆက္လုပ္ေနမွာျဖစ္ပါတယ္။

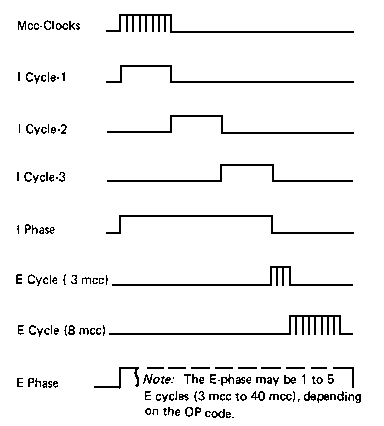
အခုအခ်ိန္အထိ အလုပ္တစ္ခုဟာ Clock အျဖစ္သာ အလုပ္လုပ္ေနတယ္လို႔ ယူဆေနတာပါ အဲဒီ့လိုဆိုရင္အလြန္ပဲေႏွးပါလိမ့္မယ္ ေနာက္ၿပီးေတာ့ Processor ရဲ႕အစိတ္အပိုင္းေတြဟာ အလုပ္အျပည့္အဝ အလုပ္ႏိုင္ပါဘူး။ ပံုမွန္အားျဖင့္ IF ဟာ တစ္ႀကိမ္အလုပ္လုပ္ၿပီးရင္ ေနာက္ထပ္ IF မေရာက္မခ်င္း Clock ေလးခု အားေနပါတယ္ အဲဒီ့ေတာ့ အစိတ္အပိုင္း ၅ ခုလံုးသာ တစ္ၿပိဳင္တည္း အလုပ္လုပ္ႏိုင္ရင္ လက္ဆင့္ကမ္းအလုပ္လုပ္သလို အၿပိဳင္အလုပ္လုပ္ႏိုင္ပါတယ္။ ဥပမာအားျဖင့္ IF အလုပ္ၿပီးလို႔ ID ကိုအလုပ္ကို လက္ဆင့္ကမ္းလုိက္ၿပီးရင္ IF အေနနဲ႔ ေနာက္ထပ္ Instruction တစ္ခုကိုယူၿပီးေတာ့ IF အလုပ္ထပ္လုပ္လို႔ရပါတယ္ အဲဒါဆိုရင္ အလုပ္စစခ်င္း Clock ေလးခုကလြဲရင္ ေနာက္အႀကိမ္ေတြမွာ Clock တစ္ခုမွာ Instruction တစ္ခုေပးႏိုင္ပါလိမ့္မယ္။ အဲဒါမ်ိဳးအလုပ္လုပ္တာကို Pipelining လို႔ေခၚပါတယ္။ ေအာက္ကပံုမွာၾကည့္ပါ

အေပၚမွာျပထားသလိုဆိုရင္ အလုပ္ေတြက Clock တစ္ခုမွာ Instruction တစ္ခုေတာ့ ၿပီးေအာင္လုပ္ႏိုင္သြားပါတယ္ အရင္လို Clock ေတြအမ်ားႀကီးမလိုေတာ့ဘူးေပါ့။ ေနာက္တစ္ဆင့္အေနနဲ႔ Clock တစ္ခုမွာ Multiple Instruction ဘယ္လိုလုပ္မလဲဆိုတာ စဥ္းစားရျပန္တယ္။ အယူအဆအားျဖင့္ ရွင္းလင္းပါတယ္ Pipeline တစ္ခုဟာ Single clock per instruction လုပ္ေပးႏိုင္ရင္ Multiple Pipeline ဆိုရင္ Single clock per multiple instruction အလုပ္လုပ္ႏိုင္ပါလိမ့္မယ္ အဲဒါမ်ိဳးကို Superscalar လို႔ေခၚပါတယ္။ ေအာက္မွာျပထားတဲ့ Figure ကိုၾကည့္ပါ Double Pipeline ျဖစ္တဲ့အတြက္ Single clock per double instruction အလုပ္လုပ္ေနတာ ေတြ႔ရပါလိမ့္မယ္။

| |||||||||||
 - In a computer, the clock cycle is the time between two adjacent pulses of the
- In a computer, the clock cycle is the time between two adjacent pulses of the ကိုလူပ်ိဳၾကီး ႏွင့္ အျခားရပ္ျခားဆိုဒ္မ်ားမွ မွီျငမ္းသည္...
Labels: A+, Computer-IV, Knowledges-II







KKZ Myanmar Unicode Keyboard





MoneTineKeyboard

Like လုပ်ထားနိုင်ပါတယ်

Labels
ဧည့်သည်တော်များခင်ဗျာ
- အခုဖတ်မည့် Post သည် လိင်မှု ပိုင်းဆိုင် ရာများ ကိုရေးသားထားခြင်းဖြစ်ပါသည်......
- သို့သော်ကျွန်တော်တို့ ရေးသား တင်ပြထားရခြင်းသည် ကျန်းမာရေး အတွက် သိထားနားလည် ထားသင့်သည် ဟုယူဆသော်ကြောင့်ဖြစ်ပါသည်.......
- ကျွန်တော်တို့၏ ဆောင်ပုဒ်သည်"ဘယ်အရာမဆို အားလုံးကို လုံးဝမတတ်ရင်နေ သိထား နားလည် ထားနိုင်ရင် ပိုကောင်းတယ်.." ဟု ဖြစ်ပါသည်..

ဧည့်သည်တော်များခင်ဗျာ
- အခုဖတ်မည့် Post သည် လိင်မှု ပိုင်းဆိုင် ရာများ ကိုရေးသားထားခြင်းဖြစ်ပါသည်......
- သို့သော်ကျွန်တော်တို့ ရေးသား တင်ပြထားရခြင်းသည် ကျန်းမာရေး အတွက် သိထားနားလည် ထားသင့်သည် ဟုယူဆသော်ကြောင့်ဖြစ်ပါသည်.......
- ကျွန်တော်တို့၏ ဆောင်ပုဒ်သည်"ဘယ်အရာမဆို အားလုံးကို လုံးဝမတတ်ရင်နေ သိထား နားလည် ထားနိုင်ရင် ပိုကောင်းတယ်.." ဟု ဖြစ်ပါသည်..
ဧည့်သည်တော်များခင်ဗျာ
- အခုဖတ်မည့် Post သည် လိင်မှု ပိုင်းဆိုင် ရာများ ကိုရေးသားထားခြင်းဖြစ်ပါသည်......
- သို့သော်ကျွန်တော်တို့ ရေးသား တင်ပြထားရခြင်းသည် ကျန်းမာရေး အတွက် သိထားနားလည် ထားသင့်သည် ဟုယူဆသော်ကြောင့်ဖြစ်ပါသည်.......
- ကျွန်တော်တို့၏ ဆောင်ပုဒ်သည်"ဘယ်အရာမဆို အားလုံးကို လုံးဝမတတ်ရင်နေ သိထား နားလည် ထားနိုင်ရင် ပိုကောင်းတယ်.." ဟု ဖြစ်ပါသည်..
ဧည့်သည်တော်များခင်ဗျာ
- အခုဖတ်မည့် Post သည် လိင်မှု ပိုင်းဆိုင် ရာများ ကိုရေးသားထားခြင်းဖြစ်ပါသည်......
- သို့သော်ကျွန်တော်တို့ ရေးသား တင်ပြထားရခြင်းသည် ကျန်းမာရေး အတွက် သိထားနားလည် ထားသင့်သည် ဟုယူဆသော်ကြောင့်ဖြစ်ပါသည်.......
- ကျွန်တော်တို့၏ ဆောင်ပုဒ်သည်"ဘယ်အရာမဆို အားလုံးကို လုံးဝမတတ်ရင်နေ သိထား နားလည် ထားနိုင်ရင် ပိုကောင်းတယ်.." ဟု ဖြစ်ပါသည်..
ဧည့်သည်တော်များခင်ဗျာ
- အခုဖတ်မည့် Post သည် လိင်မှု ပိုင်းဆိုင် ရာများ ကိုရေးသားထားခြင်းဖြစ်ပါသည်......
- သို့သော်ကျွန်တော်တို့ ရေးသား တင်ပြထားရခြင်းသည် ကျန်းမာရေး အတွက် သိထားနားလည် ထားသင့်သည် ဟုယူဆသော်ကြောင့်ဖြစ်ပါသည်.......
- ကျွန်တော်တို့၏ ဆောင်ပုဒ်သည်"ဘယ်အရာမဆို အားလုံးကို လုံးဝမတတ်ရင်နေ သိထား နားလည် ထားနိုင်ရင် ပိုကောင်းတယ်.." ဟု ဖြစ်ပါသည်..
ဧည့်သည်တော်များခင်ဗျာ
- အခုဖတ်မည့် Post သည် လိင်မှု ပိုင်းဆိုင် ရာများ ကိုရေးသားထားခြင်းဖြစ်ပါသည်......
- သို့သော်ကျွန်တော်တို့ ရေးသား တင်ပြထားရခြင်းသည် ကျန်းမာရေး အတွက် သိထားနားလည် ထားသင့်သည် ဟုယူဆသော်ကြောင့်ဖြစ်ပါသည်.......
- ကျွန်တော်တို့၏ ဆောင်ပုဒ်သည်"ဘယ်အရာမဆို အားလုံးကို လုံးဝမတတ်ရင်နေ သိထား နားလည် ထားနိုင်ရင် ပိုကောင်းတယ်.." ဟု ဖြစ်ပါသည်..
ဧည့်သည်တော်များခင်ဗျာ
- အခုဖတ်မည့် Post သည် လိင်မှု ပိုင်းဆိုင် ရာများ ကိုရေးသားထားခြင်းဖြစ်ပါသည်......
- သို့သော်ကျွန်တော်တို့ ရေးသား တင်ပြထားရခြင်းသည် ကျန်းမာရေး အတွက် သိထားနားလည် ထားသင့်သည် ဟုယူဆသော်ကြောင့်ဖြစ်ပါသည်.......
- ကျွန်တော်တို့၏ ဆောင်ပုဒ်သည်"ဘယ်အရာမဆို အားလုံးကို လုံးဝမတတ်ရင်နေ သိထား နားလည် ထားနိုင်ရင် ပိုကောင်းတယ်.." ဟု ဖြစ်ပါသည်..
ဧည့်သည်တော်များခင်ဗျာ
- အခုဖတ်မည့် Post သည် လိင်မှု ပိုင်းဆိုင် ရာများ ကိုရေးသားထားခြင်းဖြစ်ပါသည်......
- သို့သော်ကျွန်တော်တို့ ရေးသား တင်ပြထားရခြင်းသည် ကျန်းမာရေး အတွက် သိထားနားလည် ထားသင့်သည် ဟုယူဆသော်ကြောင့်ဖြစ်ပါသည်.......
- ကျွန်တော်တို့၏ ဆောင်ပုဒ်သည်"ဘယ်အရာမဆို အားလုံးကို လုံးဝမတတ်ရင်နေ သိထား နားလည် ထားနိုင်ရင် ပိုကောင်းတယ်.." ဟု ဖြစ်ပါသည်..
ဧည့်သည်တော်များခင်ဗျာ
- အခုဖတ်မည့် Post သည် လိင်မှု ပိုင်းဆိုင် ရာများ ကိုရေးသားထားခြင်းဖြစ်ပါသည်......
- သို့သော်ကျွန်တော်တို့ ရေးသား တင်ပြထားရခြင်းသည် ကျန်းမာရေး အတွက် သိထားနားလည် ထားသင့်သည် ဟုယူဆသော်ကြောင့်ဖြစ်ပါသည်.......
- ကျွန်တော်တို့၏ ဆောင်ပုဒ်သည်"ဘယ်အရာမဆို အားလုံးကို လုံးဝမတတ်ရင်နေ သိထား နားလည် ထားနိုင်ရင် ပိုကောင်းတယ်.." ဟု ဖြစ်ပါသည်..
ဧည့်သည်တော်များခင်ဗျာ
- အခုဖတ်မည့် Post သည် လိင်မှု ပိုင်းဆိုင် ရာများ ကိုရေးသားထားခြင်းဖြစ်ပါသည်......
- သို့သော်ကျွန်တော်တို့ ရေးသား တင်ပြထားရခြင်းသည် ကျန်းမာရေး အတွက် သိထားနားလည် ထားသင့်သည် ဟုယူဆသော်ကြောင့်ဖြစ်ပါသည်.......
- ကျွန်တော်တို့၏ ဆောင်ပုဒ်သည်"ဘယ်အရာမဆို အားလုံးကို လုံးဝမတတ်ရင်နေ သိထား နားလည် ထားနိုင်ရင် ပိုကောင်းတယ်.." ဟု ဖြစ်ပါသည်..
ဧည့်သည်တော်များခင်ဗျာ
- အခုဖတ်မည့် Post သည် လိင်မှု ပိုင်းဆိုင် ရာများ ကိုရေးသားထားခြင်းဖြစ်ပါသည်......
- သို့သော်ကျွန်တော်တို့ ရေးသား တင်ပြထားရခြင်းသည် ကျန်းမာရေး အတွက် သိထားနားလည် ထားသင့်သည် ဟုယူဆသော်ကြောင့်ဖြစ်ပါသည်.......
- ကျွန်တော်တို့၏ ဆောင်ပုဒ်သည်"ဘယ်အရာမဆို အားလုံးကို လုံးဝမတတ်ရင်နေ သိထား နားလည် ထားနိုင်ရင် ပိုကောင်းတယ်.." ဟု ဖြစ်ပါသည်..
ဧည့်သည်တော်များခင်ဗျာ
- အခုဖတ်မည့် Post သည် လိင်မှု ပိုင်းဆိုင် ရာများ ကိုရေးသားထားခြင်းဖြစ်ပါသည်......
- သို့သော်ကျွန်တော်တို့ ရေးသား တင်ပြထားရခြင်းသည် ကျန်းမာရေး အတွက် သိထားနားလည် ထားသင့်သည် ဟုယူဆသော်ကြောင့်ဖြစ်ပါသည်.......
- ကျွန်တော်တို့၏ ဆောင်ပုဒ်သည်"ဘယ်အရာမဆို အားလုံးကို လုံးဝမတတ်ရင်နေ သိထား နားလည် ထားနိုင်ရင် ပိုကောင်းတယ်.." ဟု ဖြစ်ပါသည်..
ဧည့်သည်တော်များခင်ဗျာ
- အခုဖတ်မည့် Post သည် လိင်မှု ပိုင်းဆိုင် ရာများ ကိုရေးသားထားခြင်းဖြစ်ပါသည်......
- သို့သော်ကျွန်တော်တို့ ရေးသား တင်ပြထားရခြင်းသည် ကျန်းမာရေး အတွက် သိထားနားလည် ထားသင့်သည် ဟုယူဆသော်ကြောင့်ဖြစ်ပါသည်.......
- ကျွန်တော်တို့၏ ဆောင်ပုဒ်သည်"ဘယ်အရာမဆို အားလုံးကို လုံးဝမတတ်ရင်နေ သိထား နားလည် ထားနိုင်ရင် ပိုကောင်းတယ်.." ဟု ဖြစ်ပါသည်..
ဧည့်သည်တော်များခင်ဗျာ
- အခုဖတ်မည့် Post သည် လိင်မှု ပိုင်းဆိုင် ရာများ ကိုရေးသားထားခြင်းဖြစ်ပါသည်......
- သို့သော်ကျွန်တော်တို့ ရေးသား တင်ပြထားရခြင်းသည် ကျန်းမာရေး အတွက် သိထားနားလည် ထားသင့်သည် ဟုယူဆသော်ကြောင့်ဖြစ်ပါသည်.......
- ကျွန်တော်တို့၏ ဆောင်ပုဒ်သည်"ဘယ်အရာမဆို အားလုံးကို လုံးဝမတတ်ရင်နေ သိထား နားလည် ထားနိုင်ရင် ပိုကောင်းတယ်.." ဟု ဖြစ်ပါသည်..
ဧည့်သည်တော်များခင်ဗျာ
- အခုဖတ်မည့် Post သည် လိင်မှု ပိုင်းဆိုင် ရာများ ကိုရေးသားထားခြင်းဖြစ်ပါသည်......
- သို့သော်ကျွန်တော်တို့ ရေးသား တင်ပြထားရခြင်းသည် ကျန်းမာရေး အတွက် သိထားနားလည် ထားသင့်သည် ဟုယူဆသော်ကြောင့်ဖြစ်ပါသည်.......
- ကျွန်တော်တို့၏ ဆောင်ပုဒ်သည်"ဘယ်အရာမဆို အားလုံးကို လုံးဝမတတ်ရင်နေ သိထား နားလည် ထားနိုင်ရင် ပိုကောင်းတယ်.." ဟု ဖြစ်ပါသည်..
ဧည့်သည်တော်များခင်ဗျာ
- အခုဖတ်မည့် Post သည် လိင်မှု ပိုင်းဆိုင် ရာများ ကိုရေးသားထားခြင်းဖြစ်ပါသည်......
- သို့သော်ကျွန်တော်တို့ ရေးသား တင်ပြထားရခြင်းသည် ကျန်းမာရေး အတွက် သိထားနားလည် ထားသင့်သည် ဟုယူဆသော်ကြောင့်ဖြစ်ပါသည်.......
- ကျွန်တော်တို့၏ ဆောင်ပုဒ်သည်"ဘယ်အရာမဆို အားလုံးကို လုံးဝမတတ်ရင်နေ သိထား နားလည် ထားနိုင်ရင် ပိုကောင်းတယ်.." ဟု ဖြစ်ပါသည်..
ဧည့်သည်တော်များခင်ဗျာ
- အခုဖတ်မည့် Post သည် လိင်မှု ပိုင်းဆိုင် ရာများ ကိုရေးသားထားခြင်းဖြစ်ပါသည်......
- သို့သော်ကျွန်တော်တို့ ရေးသား တင်ပြထားရခြင်းသည် ကျန်းမာရေး အတွက် သိထားနားလည် ထားသင့်သည် ဟုယူဆသော်ကြောင့်ဖြစ်ပါသည်.......
- ကျွန်တော်တို့၏ ဆောင်ပုဒ်သည်"ဘယ်အရာမဆို အားလုံးကို လုံးဝမတတ်ရင်နေ သိထား နားလည် ထားနိုင်ရင် ပိုကောင်းတယ်.." ဟု ဖြစ်ပါသည်..
ဧည့်သည်တော်များခင်ဗျာ
- အခုဖတ်မည့် Post သည် လိင်မှု ပိုင်းဆိုင် ရာများ ကိုရေးသားထားခြင်းဖြစ်ပါသည်......
- သို့သော်ကျွန်တော်တို့ ရေးသား တင်ပြထားရခြင်းသည် ကျန်းမာရေး အတွက် သိထားနားလည် ထားသင့်သည် ဟုယူဆသော်ကြောင့်ဖြစ်ပါသည်.......
- ကျွန်တော်တို့၏ ဆောင်ပုဒ်သည်"ဘယ်အရာမဆို အားလုံးကို လုံးဝမတတ်ရင်နေ သိထား နားလည် ထားနိုင်ရင် ပိုကောင်းတယ်.." ဟု ဖြစ်ပါသည်..
ဧည့်သည်တော်များခင်ဗျာ
- အခုဖတ်မည့် Post သည် လိင်မှု ပိုင်းဆိုင် ရာများ ကိုရေးသားထားခြင်းဖြစ်ပါသည်......
- သို့သော်ကျွန်တော်တို့ ရေးသား တင်ပြထားရခြင်းသည် ကျန်းမာရေး အတွက် သိထားနားလည် ထားသင့်သည် ဟုယူဆသော်ကြောင့်ဖြစ်ပါသည်.......
- ကျွန်တော်တို့၏ ဆောင်ပုဒ်သည်"ဘယ်အရာမဆို အားလုံးကို လုံးဝမတတ်ရင်နေ သိထား နားလည် ထားနိုင်ရင် ပိုကောင်းတယ်.." ဟု ဖြစ်ပါသည်..
ဧည့်သည်တော်များခင်ဗျာ
- အခုဖတ်မည့် Post သည် လိင်မှု ပိုင်းဆိုင် ရာများ ကိုရေးသားထားခြင်းဖြစ်ပါသည်......
- သို့သော်ကျွန်တော်တို့ ရေးသား တင်ပြထားရခြင်းသည် ကျန်းမာရေး အတွက် သိထားနားလည် ထားသင့်သည် ဟုယူဆသော်ကြောင့်ဖြစ်ပါသည်.......
- ကျွန်တော်တို့၏ ဆောင်ပုဒ်သည်"ဘယ်အရာမဆို အားလုံးကို လုံးဝမတတ်ရင်နေ သိထား နားလည် ထားနိုင်ရင် ပိုကောင်းတယ်.." ဟု ဖြစ်ပါသည်..
ဧည့်သည်တော်များခင်ဗျာ
- အခုဖတ်မည့် Post သည် လိင်မှု ပိုင်းဆိုင် ရာများ ကိုရေးသားထားခြင်းဖြစ်ပါသည်......
- သို့သော်ကျွန်တော်တို့ ရေးသား တင်ပြထားရခြင်းသည် ကျန်းမာရေး အတွက် သိထားနားလည် ထားသင့်သည် ဟုယူဆသော်ကြောင့်ဖြစ်ပါသည်.......
- ကျွန်တော်တို့၏ ဆောင်ပုဒ်သည်"ဘယ်အရာမဆို အားလုံးကို လုံးဝမတတ်ရင်နေ သိထား နားလည် ထားနိုင်ရင် ပိုကောင်းတယ်.." ဟု ဖြစ်ပါသည်..
ဧည့်သည်တော်များခင်ဗျာ
- အခုဖတ်မည့် Post သည် လိင်မှု ပိုင်းဆိုင် ရာများ ကိုရေးသားထားခြင်းဖြစ်ပါသည်......
- သို့သော်ကျွန်တော်တို့ ရေးသား တင်ပြထားရခြင်းသည် ကျန်းမာရေး အတွက် သိထားနားလည် ထားသင့်သည် ဟုယူဆသော်ကြောင့်ဖြစ်ပါသည်.......
- ကျွန်တော်တို့၏ ဆောင်ပုဒ်သည်"ဘယ်အရာမဆို အားလုံးကို လုံးဝမတတ်ရင်နေ သိထား နားလည် ထားနိုင်ရင် ပိုကောင်းတယ်.." ဟု ဖြစ်ပါသည်..
ဧည့်သည်တော်များခင်ဗျာ
- အခုဖတ်မည့် Post သည် လိင်မှု ပိုင်းဆိုင် ရာများ ကိုရေးသားထားခြင်းဖြစ်ပါသည်......
- သို့သော်ကျွန်တော်တို့ ရေးသား တင်ပြထားရခြင်းသည် ကျန်းမာရေး အတွက် သိထားနားလည် ထားသင့်သည် ဟုယူဆသော်ကြောင့်ဖြစ်ပါသည်.......
- ကျွန်တော်တို့၏ ဆောင်ပုဒ်သည်"ဘယ်အရာမဆို အားလုံးကို လုံးဝမတတ်ရင်နေ သိထား နားလည် ထားနိုင်ရင် ပိုကောင်းတယ်.." ဟု ဖြစ်ပါသည်..
ဧည့်သည်တော်များခင်ဗျာ
- အခုဖတ်မည့် Post သည် လိင်မှု ပိုင်းဆိုင် ရာများ ကိုရေးသားထားခြင်းဖြစ်ပါသည်......
- သို့သော်ကျွန်တော်တို့ ရေးသား တင်ပြထားရခြင်းသည် ကျန်းမာရေး အတွက် သိထားနားလည် ထားသင့်သည် ဟုယူဆသော်ကြောင့်ဖြစ်ပါသည်.......
- ကျွန်တော်တို့၏ ဆောင်ပုဒ်သည်"ဘယ်အရာမဆို အားလုံးကို လုံးဝမတတ်ရင်နေ သိထား နားလည် ထားနိုင်ရင် ပိုကောင်းတယ်.." ဟု ဖြစ်ပါသည်..
ဧည့်သည်တော်များခင်ဗျာ
- အခုဖတ်မည့် Post သည် လိင်မှု ပိုင်းဆိုင် ရာများ ကိုရေးသားထားခြင်းဖြစ်ပါသည်......
- သို့သော်ကျွန်တော်တို့ ရေးသား တင်ပြထားရခြင်းသည် ကျန်းမာရေး အတွက် သိထားနားလည် ထားသင့်သည် ဟုယူဆသော်ကြောင့်ဖြစ်ပါသည်.......
- ကျွန်တော်တို့၏ ဆောင်ပုဒ်သည်"ဘယ်အရာမဆို အားလုံးကို လုံးဝမတတ်ရင်နေ သိထား နားလည် ထားနိုင်ရင် ပိုကောင်းတယ်.." ဟု ဖြစ်ပါသည်..
ဧည့်သည်တော်များခင်ဗျာ
- အခုဖတ်မည့် Post သည် လိင်မှု ပိုင်းဆိုင် ရာများ ကိုရေးသားထားခြင်းဖြစ်ပါသည်......
- သို့သော်ကျွန်တော်တို့ ရေးသား တင်ပြထားရခြင်းသည် ကျန်းမာရေး အတွက် သိထားနားလည် ထားသင့်သည် ဟုယူဆသော်ကြောင့်ဖြစ်ပါသည်.......
- ကျွန်တော်တို့၏ ဆောင်ပုဒ်သည်"ဘယ်အရာမဆို အားလုံးကို လုံးဝမတတ်ရင်နေ သိထား နားလည် ထားနိုင်ရင် ပိုကောင်းတယ်.." ဟု ဖြစ်ပါသည်..
ဧည့်သည်တော်များခင်ဗျာ
- အခုဖတ်မည့် Post သည် လိင်မှု ပိုင်းဆိုင် ရာများ ကိုရေးသားထားခြင်းဖြစ်ပါသည်......
- သို့သော်ကျွန်တော်တို့ ရေးသား တင်ပြထားရခြင်းသည် ကျန်းမာရေး အတွက် သိထားနားလည် ထားသင့်သည် ဟုယူဆသော်ကြောင့်ဖြစ်ပါသည်.......
- ကျွန်တော်တို့၏ ဆောင်ပုဒ်သည်"ဘယ်အရာမဆို အားလုံးကို လုံးဝမတတ်ရင်နေ သိထား နားလည် ထားနိုင်ရင် ပိုကောင်းတယ်.." ဟု ဖြစ်ပါသည်..
ဧည့်သည်တော်များခင်ဗျာ
- အခုဖတ်မည့် Post သည် လိင်မှု ပိုင်းဆိုင် ရာများ ကိုရေးသားထားခြင်းဖြစ်ပါသည်......
- သို့သော်ကျွန်တော်တို့ ရေးသား တင်ပြထားရခြင်းသည် ကျန်းမာရေး အတွက် သိထားနားလည် ထားသင့်သည် ဟုယူဆသော်ကြောင့်ဖြစ်ပါသည်.......
- ကျွန်တော်တို့၏ ဆောင်ပုဒ်သည်"ဘယ်အရာမဆို အားလုံးကို လုံးဝမတတ်ရင်နေ သိထား နားလည် ထားနိုင်ရင် ပိုကောင်းတယ်.." ဟု ဖြစ်ပါသည်..
ဧည့်သည်တော်များခင်ဗျာ
- အခုဖတ်မည့် Post သည် လိင်မှု ပိုင်းဆိုင် ရာများ ကိုရေးသားထားခြင်းဖြစ်ပါသည်......
- သို့သော်ကျွန်တော်တို့ ရေးသား တင်ပြထားရခြင်းသည် ကျန်းမာရေး အတွက် သိထားနားလည် ထားသင့်သည် ဟုယူဆသော်ကြောင့်ဖြစ်ပါသည်.......
- ကျွန်တော်တို့၏ ဆောင်ပုဒ်သည်"ဘယ်အရာမဆို အားလုံးကို လုံးဝမတတ်ရင်နေ သိထား နားလည် ထားနိုင်ရင် ပိုကောင်းတယ်.." ဟု ဖြစ်ပါသည်..
ဧည့်သည်တော်များခင်ဗျာ
- အခုဖတ်မည့် Post သည် လိင်မှု ပိုင်းဆိုင် ရာများ ကိုရေးသားထားခြင်းဖြစ်ပါသည်......
- သို့သော်ကျွန်တော်တို့ ရေးသား တင်ပြထားရခြင်းသည် ကျန်းမာရေး အတွက် သိထားနားလည် ထားသင့်သည် ဟုယူဆသော်ကြောင့်ဖြစ်ပါသည်.......
- ကျွန်တော်တို့၏ ဆောင်ပုဒ်သည်"ဘယ်အရာမဆို အားလုံးကို လုံးဝမတတ်ရင်နေ သိထား နားလည် ထားနိုင်ရင် ပိုကောင်းတယ်.." ဟု ဖြစ်ပါသည်..
ဧည့်သည်တော်များခင်ဗျာ
- အခုဖတ်မည့် Post သည် လိင်မှု ပိုင်းဆိုင် ရာများ ကိုရေးသားထားခြင်းဖြစ်ပါသည်......
- သို့သော်ကျွန်တော်တို့ ရေးသား တင်ပြထားရခြင်းသည် ကျန်းမာရေး အတွက် သိထားနားလည် ထားသင့်သည် ဟုယူဆသော်ကြောင့်ဖြစ်ပါသည်.......
- ကျွန်တော်တို့၏ ဆောင်ပုဒ်သည်"ဘယ်အရာမဆို အားလုံးကို လုံးဝမတတ်ရင်နေ သိထား နားလည် ထားနိုင်ရင် ပိုကောင်းတယ်.." ဟု ဖြစ်ပါသည်..
ဧည့်သည်တော်များခင်ဗျာ
- အခုဖတ်မည့် Post သည် လိင်မှု ပိုင်းဆိုင် ရာများ ကိုရေးသားထားခြင်းဖြစ်ပါသည်......
- သို့သော်ကျွန်တော်တို့ ရေးသား တင်ပြထားရခြင်းသည် ကျန်းမာရေး အတွက် သိထားနားလည် ထားသင့်သည် ဟုယူဆသော်ကြောင့်ဖြစ်ပါသည်.......
- ကျွန်တော်တို့၏ ဆောင်ပုဒ်သည်"ဘယ်အရာမဆို အားလုံးကို လုံးဝမတတ်ရင်နေ သိထား နားလည် ထားနိုင်ရင် ပိုကောင်းတယ်.." ဟု ဖြစ်ပါသည်..
ဧည့်သည်တော်များခင်ဗျာ
- အခုဖတ်မည့် Post သည် လိင်မှု ပိုင်းဆိုင် ရာများ ကိုရေးသားထားခြင်းဖြစ်ပါသည်......
- သို့သော်ကျွန်တော်တို့ ရေးသား တင်ပြထားရခြင်းသည် ကျန်းမာရေး အတွက် သိထားနားလည် ထားသင့်သည် ဟုယူဆသော်ကြောင့်ဖြစ်ပါသည်.......
- ကျွန်တော်တို့၏ ဆောင်ပုဒ်သည်"ဘယ်အရာမဆို အားလုံးကို လုံးဝမတတ်ရင်နေ သိထား နားလည် ထားနိုင်ရင် ပိုကောင်းတယ်.." ဟု ဖြစ်ပါသည်..
ဧည့်သည်တော်များခင်ဗျာ
- အခုဖတ်မည့် Post သည် လိင်မှု ပိုင်းဆိုင် ရာများ ကိုရေးသားထားခြင်းဖြစ်ပါသည်......
- သို့သော်ကျွန်တော်တို့ ရေးသား တင်ပြထားရခြင်းသည် ကျန်းမာရေး အတွက် သိထားနားလည် ထားသင့်သည် ဟုယူဆသော်ကြောင့်ဖြစ်ပါသည်.......
- ကျွန်တော်တို့၏ ဆောင်ပုဒ်သည်"ဘယ်အရာမဆို အားလုံးကို လုံးဝမတတ်ရင်နေ သိထား နားလည် ထားနိုင်ရင် ပိုကောင်းတယ်.." ဟု ဖြစ်ပါသည်..
ဧည့်သည်တော်များခင်ဗျာ
- အခုဖတ်မည့် Post သည် လိင်မှု ပိုင်းဆိုင် ရာများ ကိုရေးသားထားခြင်းဖြစ်ပါသည်......
- သို့သော်ကျွန်တော်တို့ ရေးသား တင်ပြထားရခြင်းသည် ကျန်းမာရေး အတွက် သိထားနားလည် ထားသင့်သည် ဟုယူဆသော်ကြောင့်ဖြစ်ပါသည်.......
- ကျွန်တော်တို့၏ ဆောင်ပုဒ်သည်"ဘယ်အရာမဆို အားလုံးကို လုံးဝမတတ်ရင်နေ သိထား နားလည် ထားနိုင်ရင် ပိုကောင်းတယ်.." ဟု ဖြစ်ပါသည်..
ဧည့်သည်တော်များခင်ဗျာ
- အခုဖတ်မည့် Post သည် လိင်မှု ပိုင်းဆိုင် ရာများ ကိုရေးသားထားခြင်းဖြစ်ပါသည်......
- သို့သော်ကျွန်တော်တို့ ရေးသား တင်ပြထားရခြင်းသည် ကျန်းမာရေး အတွက် သိထားနားလည် ထားသင့်သည် ဟုယူဆသော်ကြောင့်ဖြစ်ပါသည်.......
- ကျွန်တော်တို့၏ ဆောင်ပုဒ်သည်"ဘယ်အရာမဆို အားလုံးကို လုံးဝမတတ်ရင်နေ သိထား နားလည် ထားနိုင်ရင် ပိုကောင်းတယ်.." ဟု ဖြစ်ပါသည်..
ဧည့်သည်တော်များခင်ဗျာ
- အခုဖတ်မည့် Post သည် လိင်မှု ပိုင်းဆိုင် ရာများ ကိုရေးသားထားခြင်းဖြစ်ပါသည်......
- သို့သော်ကျွန်တော်တို့ ရေးသား တင်ပြထားရခြင်းသည် ကျန်းမာရေး အတွက် သိထားနားလည် ထားသင့်သည် ဟုယူဆသော်ကြောင့်ဖြစ်ပါသည်.......
- ကျွန်တော်တို့၏ ဆောင်ပုဒ်သည်"ဘယ်အရာမဆို အားလုံးကို လုံးဝမတတ်ရင်နေ သိထား နားလည် ထားနိုင်ရင် ပိုကောင်းတယ်.." ဟု ဖြစ်ပါသည်..
ဧည့်သည်တော်များခင်ဗျာ
- အခုဖတ်မည့် Post သည် လိင်မှု ပိုင်းဆိုင် ရာများ ကိုရေးသားထားခြင်းဖြစ်ပါသည်......
- သို့သော်ကျွန်တော်တို့ ရေးသား တင်ပြထားရခြင်းသည် ကျန်းမာရေး အတွက် သိထားနားလည် ထားသင့်သည် ဟုယူဆသော်ကြောင့်ဖြစ်ပါသည်.......
- ကျွန်တော်တို့၏ ဆောင်ပုဒ်သည်"ဘယ်အရာမဆို အားလုံးကို လုံးဝမတတ်ရင်နေ သိထား နားလည် ထားနိုင်ရင် ပိုကောင်းတယ်.." ဟု ဖြစ်ပါသည်..
ဧည့်သည်တော်များခင်ဗျာ
- အခုဖတ်မည့် Post သည် လိင်မှု ပိုင်းဆိုင် ရာများ ကိုရေးသားထားခြင်းဖြစ်ပါသည်......
- သို့သော်ကျွန်တော်တို့ ရေးသား တင်ပြထားရခြင်းသည် ကျန်းမာရေး အတွက် သိထားနားလည် ထားသင့်သည် ဟုယူဆသော်ကြောင့်ဖြစ်ပါသည်.......
- ကျွန်တော်တို့၏ ဆောင်ပုဒ်သည်"ဘယ်အရာမဆို အားလုံးကို လုံးဝမတတ်ရင်နေ သိထား နားလည် ထားနိုင်ရင် ပိုကောင်းတယ်.." ဟု ဖြစ်ပါသည်..
ဧည့်သည်တော်များခင်ဗျာ
- အခုဖတ်မည့် Post သည် လိင်မှု ပိုင်းဆိုင် ရာများ ကိုရေးသားထားခြင်းဖြစ်ပါသည်......
- သို့သော်ကျွန်တော်တို့ ရေးသား တင်ပြထားရခြင်းသည် ကျန်းမာရေး အတွက် သိထားနားလည် ထားသင့်သည် ဟုယူဆသော်ကြောင့်ဖြစ်ပါသည်.......
- ကျွန်တော်တို့၏ ဆောင်ပုဒ်သည်"ဘယ်အရာမဆို အားလုံးကို လုံးဝမတတ်ရင်နေ သိထား နားလည် ထားနိုင်ရင် ပိုကောင်းတယ်.." ဟု ဖြစ်ပါသည်..
ဧည့်သည်တော်များခင်ဗျာ
- အခုဖတ်မည့် Post သည် လိင်မှု ပိုင်းဆိုင် ရာများ ကိုရေးသားထားခြင်းဖြစ်ပါသည်......
- သို့သော်ကျွန်တော်တို့ ရေးသား တင်ပြထားရခြင်းသည် ကျန်းမာရေး အတွက် သိထားနားလည် ထားသင့်သည် ဟုယူဆသော်ကြောင့်ဖြစ်ပါသည်.......
- ကျွန်တော်တို့၏ ဆောင်ပုဒ်သည်"ဘယ်အရာမဆို အားလုံးကို လုံးဝမတတ်ရင်နေ သိထား နားလည် ထားနိုင်ရင် ပိုကောင်းတယ်.." ဟု ဖြစ်ပါသည်..
ဧည့်သည်တော်များခင်ဗျာ
- အခုဖတ်မည့် Post သည် လိင်မှု ပိုင်းဆိုင် ရာများ ကိုရေးသားထားခြင်းဖြစ်ပါသည်......
- သို့သော်ကျွန်တော်တို့ ရေးသား တင်ပြထားရခြင်းသည် ကျန်းမာရေး အတွက် သိထားနားလည် ထားသင့်သည် ဟုယူဆသော်ကြောင့်ဖြစ်ပါသည်.......
- ကျွန်တော်တို့၏ ဆောင်ပုဒ်သည်"ဘယ်အရာမဆို အားလုံးကို လုံးဝမတတ်ရင်နေ သိထား နားလည် ထားနိုင်ရင် ပိုကောင်းတယ်.." ဟု ဖြစ်ပါသည်..
ဧည့်သည်တော်များခင်ဗျာ
- အခုဖတ်မည့် Post သည် လိင်မှု ပိုင်းဆိုင် ရာများ ကိုရေးသားထားခြင်းဖြစ်ပါသည်......
- သို့သော်ကျွန်တော်တို့ ရေးသား တင်ပြထားရခြင်းသည် ကျန်းမာရေး အတွက် သိထားနားလည် ထားသင့်သည် ဟုယူဆသော်ကြောင့်ဖြစ်ပါသည်.......
- ကျွန်တော်တို့၏ ဆောင်ပုဒ်သည်"ဘယ်အရာမဆို အားလုံးကို လုံးဝမတတ်ရင်နေ သိထား နားလည် ထားနိုင်ရင် ပိုကောင်းတယ်.." ဟု ဖြစ်ပါသည်..
ဧည့်သည်တော်များခင်ဗျာ
- အခုဖတ်မည့် Post သည် လိင်မှု ပိုင်းဆိုင် ရာများ ကိုရေးသားထားခြင်းဖြစ်ပါသည်......
- သို့သော်ကျွန်တော်တို့ ရေးသား တင်ပြထားရခြင်းသည် ကျန်းမာရေး အတွက် သိထားနားလည် ထားသင့်သည် ဟုယူဆသော်ကြောင့်ဖြစ်ပါသည်.......
- ကျွန်တော်တို့၏ ဆောင်ပုဒ်သည်"ဘယ်အရာမဆို အားလုံးကို လုံးဝမတတ်ရင်နေ သိထား နားလည် ထားနိုင်ရင် ပိုကောင်းတယ်.." ဟု ဖြစ်ပါသည်..
ဧည့်သည်တော်များခင်ဗျာ
- အခုဖတ်မည့် Post သည် လိင်မှု ပိုင်းဆိုင် ရာများ ကိုရေးသားထားခြင်းဖြစ်ပါသည်......
- သို့သော်ကျွန်တော်တို့ ရေးသား တင်ပြထားရခြင်းသည် ကျန်းမာရေး အတွက် သိထားနားလည် ထားသင့်သည် ဟုယူဆသော်ကြောင့်ဖြစ်ပါသည်.......
- ကျွန်တော်တို့၏ ဆောင်ပုဒ်သည်"ဘယ်အရာမဆို အားလုံးကို လုံးဝမတတ်ရင်နေ သိထား နားလည် ထားနိုင်ရင် ပိုကောင်းတယ်.." ဟု ဖြစ်ပါသည်..
ဧည့်သည်တော်များခင်ဗျာ
- အခုဖတ်မည့် Post သည် လိင်မှု ပိုင်းဆိုင် ရာများ ကိုရေးသားထားခြင်းဖြစ်ပါသည်......
- သို့သော်ကျွန်တော်တို့ ရေးသား တင်ပြထားရခြင်းသည် ကျန်းမာရေး အတွက် သိထားနားလည် ထားသင့်သည် ဟုယူဆသော်ကြောင့်ဖြစ်ပါသည်.......
- ကျွန်တော်တို့၏ ဆောင်ပုဒ်သည်"ဘယ်အရာမဆို အားလုံးကို လုံးဝမတတ်ရင်နေ သိထား နားလည် ထားနိုင်ရင် ပိုကောင်းတယ်.." ဟု ဖြစ်ပါသည်..
ဧည့်သည်တော်များခင်ဗျာ
- အခုဖတ်မည့် Post သည် လိင်မှု ပိုင်းဆိုင် ရာများ ကိုရေးသားထားခြင်းဖြစ်ပါသည်......
- သို့သော်ကျွန်တော်တို့ ရေးသား တင်ပြထားရခြင်းသည် ကျန်းမာရေး အတွက် သိထားနားလည် ထားသင့်သည် ဟုယူဆသော်ကြောင့်ဖြစ်ပါသည်.......
- ကျွန်တော်တို့၏ ဆောင်ပုဒ်သည်"ဘယ်အရာမဆို အားလုံးကို လုံးဝမတတ်ရင်နေ သိထား နားလည် ထားနိုင်ရင် ပိုကောင်းတယ်.." ဟု ဖြစ်ပါသည်..
ဧည့်သည်တော်များခင်ဗျာ
- အခုဖတ်မည့် Post သည် လိင်မှု ပိုင်းဆိုင် ရာများ ကိုရေးသားထားခြင်းဖြစ်ပါသည်......
- သို့သော်ကျွန်တော်တို့ ရေးသား တင်ပြထားရခြင်းသည် ကျန်းမာရေး အတွက် သိထားနားလည် ထားသင့်သည် ဟုယူဆသော်ကြောင့်ဖြစ်ပါသည်.......
- ကျွန်တော်တို့၏ ဆောင်ပုဒ်သည်"ဘယ်အရာမဆို အားလုံးကို လုံးဝမတတ်ရင်နေ သိထား နားလည် ထားနိုင်ရင် ပိုကောင်းတယ်.." ဟု ဖြစ်ပါသည်..
ဧည့်သည်တော်များခင်ဗျာ
- အခုဖတ်မည့် Post သည် လိင်မှု ပိုင်းဆိုင် ရာများ ကိုရေးသားထားခြင်းဖြစ်ပါသည်......
- သို့သော်ကျွန်တော်တို့ ရေးသား တင်ပြထားရခြင်းသည် ကျန်းမာရေး အတွက် သိထားနားလည် ထားသင့်သည် ဟုယူဆသော်ကြောင့်ဖြစ်ပါသည်.......
- ကျွန်တော်တို့၏ ဆောင်ပုဒ်သည်"ဘယ်အရာမဆို အားလုံးကို လုံးဝမတတ်ရင်နေ သိထား နားလည် ထားနိုင်ရင် ပိုကောင်းတယ်.." ဟု ဖြစ်ပါသည်..
ဧည့်သည်တော်များခင်ဗျာ
- အခုဖတ်မည့် Post သည် လိင်မှု ပိုင်းဆိုင် ရာများ ကိုရေးသားထားခြင်းဖြစ်ပါသည်......
- သို့သော်ကျွန်တော်တို့ ရေးသား တင်ပြထားရခြင်းသည် ကျန်းမာရေး အတွက် သိထားနားလည် ထားသင့်သည် ဟုယူဆသော်ကြောင့်ဖြစ်ပါသည်.......
- ကျွန်တော်တို့၏ ဆောင်ပုဒ်သည်"ဘယ်အရာမဆို အားလုံးကို လုံးဝမတတ်ရင်နေ သိထား နားလည် ထားနိုင်ရင် ပိုကောင်းတယ်.." ဟု ဖြစ်ပါသည်..
ဧည့်သည်တော်များခင်ဗျာ
- အခုဖတ်မည့် Post သည် လိင်မှု ပိုင်းဆိုင် ရာများ ကိုရေးသားထားခြင်းဖြစ်ပါသည်......
- သို့သော်ကျွန်တော်တို့ ရေးသား တင်ပြထားရခြင်းသည် ကျန်းမာရေး အတွက် သိထားနားလည် ထားသင့်သည် ဟုယူဆသော်ကြောင့်ဖြစ်ပါသည်.......
- ကျွန်တော်တို့၏ ဆောင်ပုဒ်သည်"ဘယ်အရာမဆို အားလုံးကို လုံးဝမတတ်ရင်နေ သိထား နားလည် ထားနိုင်ရင် ပိုကောင်းတယ်.." ဟု ဖြစ်ပါသည်..
ဧည့်သည်တော်များခင်ဗျာ
- အခုဖတ်မည့် Post သည် လိင်မှု ပိုင်းဆိုင် ရာများ ကိုရေးသားထားခြင်းဖြစ်ပါသည်......
- သို့သော်ကျွန်တော်တို့ ရေးသား တင်ပြထားရခြင်းသည် ကျန်းမာရေး အတွက် သိထားနားလည် ထားသင့်သည် ဟုယူဆသော်ကြောင့်ဖြစ်ပါသည်.......
- ကျွန်တော်တို့၏ ဆောင်ပုဒ်သည်"ဘယ်အရာမဆို အားလုံးကို လုံးဝမတတ်ရင်နေ သိထား နားလည် ထားနိုင်ရင် ပိုကောင်းတယ်.." ဟု ဖြစ်ပါသည်..
ဧည့်သည်တော်များခင်ဗျာ
- အခုဖတ်မည့် Post သည် လိင်မှု ပိုင်းဆိုင် ရာများ ကိုရေးသားထားခြင်းဖြစ်ပါသည်......
- သို့သော်ကျွန်တော်တို့ ရေးသား တင်ပြထားရခြင်းသည် ကျန်းမာရေး အတွက် သိထားနားလည် ထားသင့်သည် ဟုယူဆသော်ကြောင့်ဖြစ်ပါသည်.......
- ကျွန်တော်တို့၏ ဆောင်ပုဒ်သည်"ဘယ်အရာမဆို အားလုံးကို လုံးဝမတတ်ရင်နေ သိထား နားလည် ထားနိုင်ရင် ပိုကောင်းတယ်.." ဟု ဖြစ်ပါသည်..
ဧည့်သည်တော်များခင်ဗျာ
- အခုဖတ်မည့် Post သည် လိင်မှု ပိုင်းဆိုင် ရာများ ကိုရေးသားထားခြင်းဖြစ်ပါသည်......
- သို့သော်ကျွန်တော်တို့ ရေးသား တင်ပြထားရခြင်းသည် ကျန်းမာရေး အတွက် သိထားနားလည် ထားသင့်သည် ဟုယူဆသော်ကြောင့်ဖြစ်ပါသည်.......
- ကျွန်တော်တို့၏ ဆောင်ပုဒ်သည်"ဘယ်အရာမဆို အားလုံးကို လုံးဝမတတ်ရင်နေ သိထား နားလည် ထားနိုင်ရင် ပိုကောင်းတယ်.." ဟု ဖြစ်ပါသည်..
ဧည့်သည်တော်များခင်ဗျာ
- အခုဖတ်မည့် Post သည် လိင်မှု ပိုင်းဆိုင် ရာများ ကိုရေးသားထားခြင်းဖြစ်ပါသည်......
- သို့သော်ကျွန်တော်တို့ ရေးသား တင်ပြထားရခြင်းသည် ကျန်းမာရေး အတွက် သိထားနားလည် ထားသင့်သည် ဟုယူဆသော်ကြောင့်ဖြစ်ပါသည်.......
- ကျွန်တော်တို့၏ ဆောင်ပုဒ်သည်"ဘယ်အရာမဆို အားလုံးကို လုံးဝမတတ်ရင်နေ သိထား နားလည် ထားနိုင်ရင် ပိုကောင်းတယ်.." ဟု ဖြစ်ပါသည်..
ဧည့်သည်တော်များခင်ဗျာ
- အခုဖတ်မည့် Post သည် လိင်မှု ပိုင်းဆိုင် ရာများ ကိုရေးသားထားခြင်းဖြစ်ပါသည်......
- သို့သော်ကျွန်တော်တို့ ရေးသား တင်ပြထားရခြင်းသည် ကျန်းမာရေး အတွက် သိထားနားလည် ထားသင့်သည် ဟုယူဆသော်ကြောင့်ဖြစ်ပါသည်.......
- ကျွန်တော်တို့၏ ဆောင်ပုဒ်သည်"ဘယ်အရာမဆို အားလုံးကို လုံးဝမတတ်ရင်နေ သိထား နားလည် ထားနိုင်ရင် ပိုကောင်းတယ်.." ဟု ဖြစ်ပါသည်..
ဧည့်သည်တော်များခင်ဗျာ
- အခုဖတ်မည့် Post သည် လိင်မှု ပိုင်းဆိုင် ရာများ ကိုရေးသားထားခြင်းဖြစ်ပါသည်......
- သို့သော်ကျွန်တော်တို့ ရေးသား တင်ပြထားရခြင်းသည် ကျန်းမာရေး အတွက် သိထားနားလည် ထားသင့်သည် ဟုယူဆသော်ကြောင့်ဖြစ်ပါသည်.......
- ကျွန်တော်တို့၏ ဆောင်ပုဒ်သည်"ဘယ်အရာမဆို အားလုံးကို လုံးဝမတတ်ရင်နေ သိထား နားလည် ထားနိုင်ရင် ပိုကောင်းတယ်.." ဟု ဖြစ်ပါသည်..
ဧည့်သည်တော်များခင်ဗျာ
- အခုဖတ်မည့် Post သည် လိင်မှု ပိုင်းဆိုင် ရာများ ကိုရေးသားထားခြင်းဖြစ်ပါသည်......
- သို့သော်ကျွန်တော်တို့ ရေးသား တင်ပြထားရခြင်းသည် ကျန်းမာရေး အတွက် သိထားနားလည် ထားသင့်သည် ဟုယူဆသော်ကြောင့်ဖြစ်ပါသည်.......
- ကျွန်တော်တို့၏ ဆောင်ပုဒ်သည်"ဘယ်အရာမဆို အားလုံးကို လုံးဝမတတ်ရင်နေ သိထား နားလည် ထားနိုင်ရင် ပိုကောင်းတယ်.." ဟု ဖြစ်ပါသည်..
ဧည့်သည်တော်များခင်ဗျာ
- အခုဖတ်မည့် Post သည် လိင်မှု ပိုင်းဆိုင် ရာများ ကိုရေးသားထားခြင်းဖြစ်ပါသည်......
- သို့သော်ကျွန်တော်တို့ ရေးသား တင်ပြထားရခြင်းသည် ကျန်းမာရေး အတွက် သိထားနားလည် ထားသင့်သည် ဟုယူဆသော်ကြောင့်ဖြစ်ပါသည်.......
- ကျွန်တော်တို့၏ ဆောင်ပုဒ်သည်"ဘယ်အရာမဆို အားလုံးကို လုံးဝမတတ်ရင်နေ သိထား နားလည် ထားနိုင်ရင် ပိုကောင်းတယ်.." ဟု ဖြစ်ပါသည်..
ဧည့်သည်တော်များခင်ဗျာ
- အခုဖတ်မည့် Post သည် လိင်မှု ပိုင်းဆိုင် ရာများ ကိုရေးသားထားခြင်းဖြစ်ပါသည်......
- သို့သော်ကျွန်တော်တို့ ရေးသား တင်ပြထားရခြင်းသည် ကျန်းမာရေး အတွက် သိထားနားလည် ထားသင့်သည် ဟုယူဆသော်ကြောင့်ဖြစ်ပါသည်.......
- ကျွန်တော်တို့၏ ဆောင်ပုဒ်သည်"ဘယ်အရာမဆို အားလုံးကို လုံးဝမတတ်ရင်နေ သိထား နားလည် ထားနိုင်ရင် ပိုကောင်းတယ်.." ဟု ဖြစ်ပါသည်..
ဧည့်သည်တော်များခင်ဗျာ
- အခုဖတ်မည့် Post သည် လိင်မှု ပိုင်းဆိုင် ရာများ ကိုရေးသားထားခြင်းဖြစ်ပါသည်......
- သို့သော်ကျွန်တော်တို့ ရေးသား တင်ပြထားရခြင်းသည် ကျန်းမာရေး အတွက် သိထားနားလည် ထားသင့်သည် ဟုယူဆသော်ကြောင့်ဖြစ်ပါသည်.......
- ကျွန်တော်တို့၏ ဆောင်ပုဒ်သည်"ဘယ်အရာမဆို အားလုံးကို လုံးဝမတတ်ရင်နေ သိထား နားလည် ထားနိုင်ရင် ပိုကောင်းတယ်.." ဟု ဖြစ်ပါသည်..
ဧည့်သည်တော်များခင်ဗျာ
- အခုဖတ်မည့် Post သည် လိင်မှု ပိုင်းဆိုင် ရာများ ကိုရေးသားထားခြင်းဖြစ်ပါသည်......
- သို့သော်ကျွန်တော်တို့ ရေးသား တင်ပြထားရခြင်းသည် ကျန်းမာရေး အတွက် သိထားနားလည် ထားသင့်သည် ဟုယူဆသော်ကြောင့်ဖြစ်ပါသည်.......
- ကျွန်တော်တို့၏ ဆောင်ပုဒ်သည်"ဘယ်အရာမဆို အားလုံးကို လုံးဝမတတ်ရင်နေ သိထား နားလည် ထားနိုင်ရင် ပိုကောင်းတယ်.." ဟု ဖြစ်ပါသည်..
ဧည့်သည်တော်များခင်ဗျာ
- အခုဖတ်မည့် Post သည် လိင်မှု ပိုင်းဆိုင် ရာများ ကိုရေးသားထားခြင်းဖြစ်ပါသည်......
- သို့သော်ကျွန်တော်တို့ ရေးသား တင်ပြထားရခြင်းသည် ကျန်းမာရေး အတွက် သိထားနားလည် ထားသင့်သည် ဟုယူဆသော်ကြောင့်ဖြစ်ပါသည်.......
- ကျွန်တော်တို့၏ ဆောင်ပုဒ်သည်"ဘယ်အရာမဆို အားလုံးကို လုံးဝမတတ်ရင်နေ သိထား နားလည် ထားနိုင်ရင် ပိုကောင်းတယ်.." ဟု ဖြစ်ပါသည်..
ဧည့်သည်တော်များခင်ဗျာ
- အခုဖတ်မည့် Post သည် လိင်မှု ပိုင်းဆိုင် ရာများ ကိုရေးသားထားခြင်းဖြစ်ပါသည်......
- သို့သော်ကျွန်တော်တို့ ရေးသား တင်ပြထားရခြင်းသည် ကျန်းမာရေး အတွက် သိထားနားလည် ထားသင့်သည် ဟုယူဆသော်ကြောင့်ဖြစ်ပါသည်.......
- ကျွန်တော်တို့၏ ဆောင်ပုဒ်သည်"ဘယ်အရာမဆို အားလုံးကို လုံးဝမတတ်ရင်နေ သိထား နားလည် ထားနိုင်ရင် ပိုကောင်းတယ်.." ဟု ဖြစ်ပါသည်..
ဧည့်သည်တော်များခင်ဗျာ
- အခုဖတ်မည့် Post သည် လိင်မှု ပိုင်းဆိုင် ရာများ ကိုရေးသားထားခြင်းဖြစ်ပါသည်......
- သို့သော်ကျွန်တော်တို့ ရေးသား တင်ပြထားရခြင်းသည် ကျန်းမာရေး အတွက် သိထားနားလည် ထားသင့်သည် ဟုယူဆသော်ကြောင့်ဖြစ်ပါသည်.......
- ကျွန်တော်တို့၏ ဆောင်ပုဒ်သည်"ဘယ်အရာမဆို အားလုံးကို လုံးဝမတတ်ရင်နေ သိထား နားလည် ထားနိုင်ရင် ပိုကောင်းတယ်.." ဟု ဖြစ်ပါသည်..
ဧည့်သည်တော်များခင်ဗျာ
- အခုဖတ်မည့် Post သည် လိင်မှု ပိုင်းဆိုင် ရာများ ကိုရေးသားထားခြင်းဖြစ်ပါသည်......
- သို့သော်ကျွန်တော်တို့ ရေးသား တင်ပြထားရခြင်းသည် ကျန်းမာရေး အတွက် သိထားနားလည် ထားသင့်သည် ဟုယူဆသော်ကြောင့်ဖြစ်ပါသည်.......
- ကျွန်တော်တို့၏ ဆောင်ပုဒ်သည်"ဘယ်အရာမဆို အားလုံးကို လုံးဝမတတ်ရင်နေ သိထား နားလည် ထားနိုင်ရင် ပိုကောင်းတယ်.." ဟု ဖြစ်ပါသည်..
ဧည့်သည်တော်များခင်ဗျာ
- အခုဖတ်မည့် Post သည် လိင်မှု ပိုင်းဆိုင် ရာများ ကိုရေးသားထားခြင်းဖြစ်ပါသည်......
- သို့သော်ကျွန်တော်တို့ ရေးသား တင်ပြထားရခြင်းသည် ကျန်းမာရေး အတွက် သိထားနားလည် ထားသင့်သည် ဟုယူဆသော်ကြောင့်ဖြစ်ပါသည်.......
- ကျွန်တော်တို့၏ ဆောင်ပုဒ်သည်"ဘယ်အရာမဆို အားလုံးကို လုံးဝမတတ်ရင်နေ သိထား နားလည် ထားနိုင်ရင် ပိုကောင်းတယ်.." ဟု ဖြစ်ပါသည်..
ဧည့်သည်တော်များခင်ဗျာ
- အခုဖတ်မည့် Post သည် လိင်မှု ပိုင်းဆိုင် ရာများ ကိုရေးသားထားခြင်းဖြစ်ပါသည်......
- သို့သော်ကျွန်တော်တို့ ရေးသား တင်ပြထားရခြင်းသည် ကျန်းမာရေး အတွက် သိထားနားလည် ထားသင့်သည် ဟုယူဆသော်ကြောင့်ဖြစ်ပါသည်.......
- ကျွန်တော်တို့၏ ဆောင်ပုဒ်သည်"ဘယ်အရာမဆို အားလုံးကို လုံးဝမတတ်ရင်နေ သိထား နားလည် ထားနိုင်ရင် ပိုကောင်းတယ်.." ဟု ဖြစ်ပါသည်..
ဧည့်သည်တော်များခင်ဗျာ
- အခုဖတ်မည့် Post သည် လိင်မှု ပိုင်းဆိုင် ရာများ ကိုရေးသားထားခြင်းဖြစ်ပါသည်......
- သို့သော်ကျွန်တော်တို့ ရေးသား တင်ပြထားရခြင်းသည် ကျန်းမာရေး အတွက် သိထားနားလည် ထားသင့်သည် ဟုယူဆသော်ကြောင့်ဖြစ်ပါသည်.......
- ကျွန်တော်တို့၏ ဆောင်ပုဒ်သည်"ဘယ်အရာမဆို အားလုံးကို လုံးဝမတတ်ရင်နေ သိထား နားလည် ထားနိုင်ရင် ပိုကောင်းတယ်.." ဟု ဖြစ်ပါသည်..


0 - ဦး မှတ်ချက်ပေးထားပါသည်
Post a Comment